黄泽桓与曹炎培盛律团队探讨3D场景生成技术突破与未来AI系统构建
黄泽桓与曹炎培盛律团队探讨3D场景生成技术突破与未来AI系统构建
Sora推动了全球模型技术的变革,在这样的形势之下,3D场景在制作动态互动人工智能系统中起到了至关重要的作用。但现阶段,仅通过一张图片来构建3D场景面临了不少挑战。值得庆幸的是,新推出的MIDI模型实现了重大突破。咱们一起来揭开这个谜团!同时,VAST的首席科学家曹炎培和北航的副教授盛律作为通讯作者,他们所领导的团队为这一成果的取得奠定了坚实的学术基础。
Sora推动了全球模型技术的变革,在这样的形势之下,3D场景在制作动态互动人工智能系统中起到了至关重要的作用。但现阶段,仅通过一张图片来构建3D场景面临了不少挑战。值得庆幸的是,新推出的MIDI模型实现了重大突破。这是为何?咱们一起来揭开这个谜团!
研究团队实力雄厚
这项研究是由VAST、北京航空航天大学、清华大学和香港大学的科研团队携手完成的。其中,北京航空航天大学的硕士研究生黄泽桓是本研究的首位作者,他专注于生成式人工智能和三维视觉领域的研究。同时,VAST的首席科学家曹炎培和北航的副教授盛律作为通讯作者,他们所领导的团队为这一成果的取得奠定了坚实的学术基础。

3D场景技术现状
目前,图像生成三维资产的技术有了显著进步。这无疑是一次质的飞跃,让三维内容创作拥有了从想象到三维形态的转换能力。但技术发展到组合场景生成阶段,单一物体生成的问题开始凸显。现在的方法生产的3D资产,就像“数字原子”,难以有效组合成“分子结构”。
核心挑战显著
单视图3D场景生成遇到了几个重要挑战。首先,从一张图片中精确区分出重叠的物体相当不易;其次,建立物理约束模型有难度,物体可能会不合理地穿透场景;再者,对场景的语义理解不够深入,难以保证物体功能和空间布局的匹配。这些问题在很大程度上限制了“可交互世界”的构建。
MIDI模型诞生
为了解决这些挑战,北航以及VAST等科研机构的研究团队推出了MIDI模型。该模型能从单张图片中生成具有高几何精度和良好实例分离能力的3D合成场景。MIDI模型的出现,为单视图3D场景生成领域注入了新的活力,也为构建交互式世界奠定了稳固的基础。
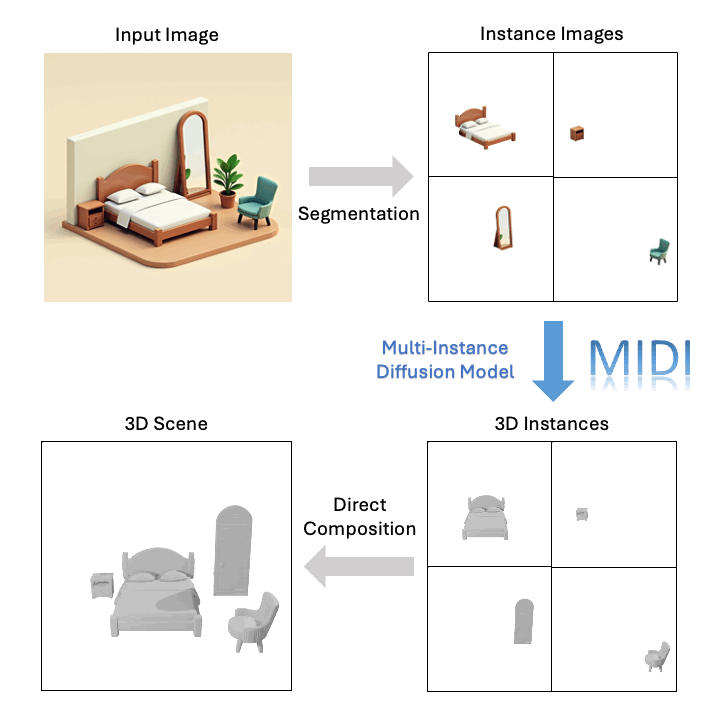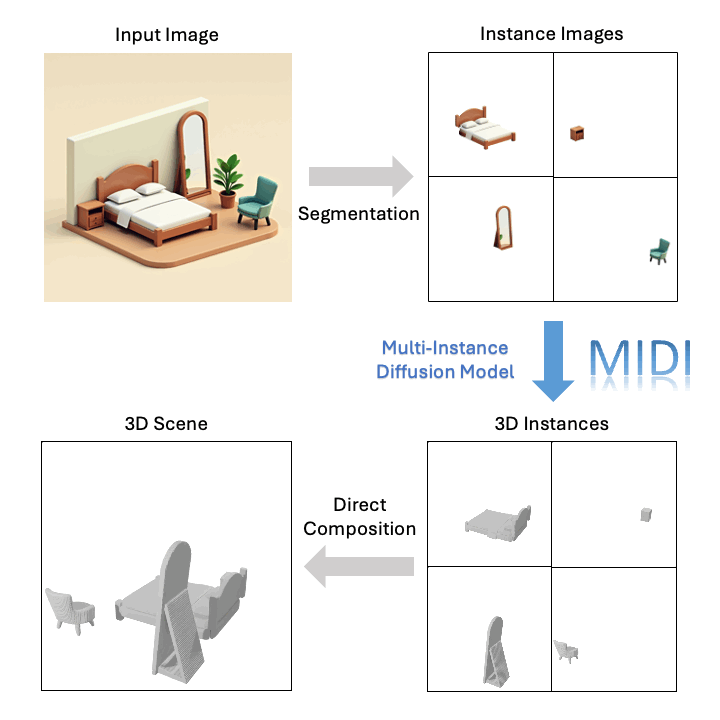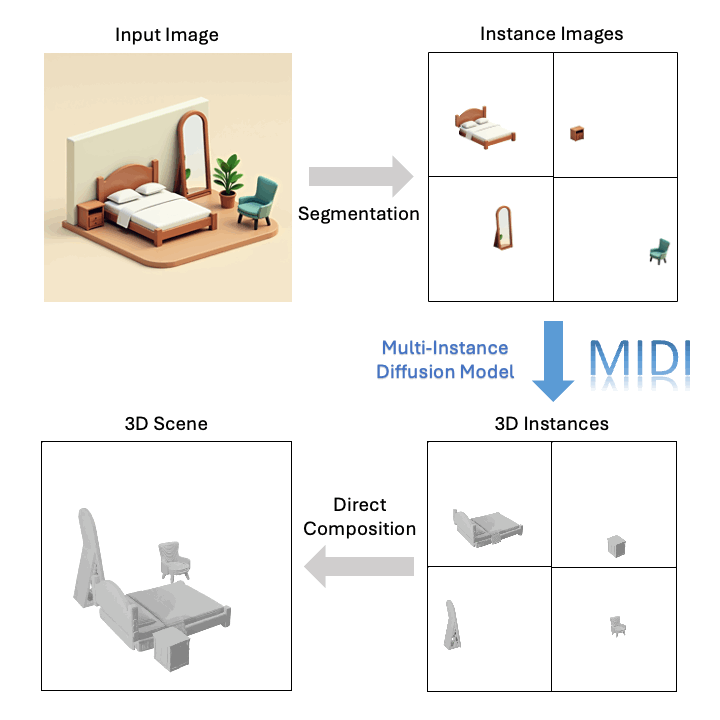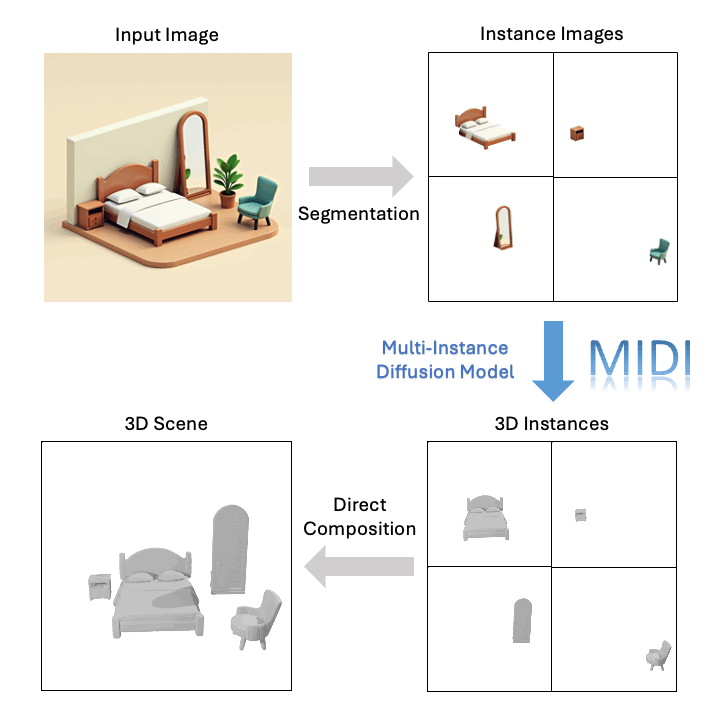
技术创新亮点
传统的3D场景重建技术操作复杂,效果并不理想。MIDI技术巧妙地应用于三维物体的建模,从而催生了多实例扩散模型的发展。它成功将单一物体转换成了多个实例。它通过去除噪声,处理多个3D实例的潜在表示,并加入交互功能,能够直接构建3D场景。它利用多实例自注意力机制,高效捕捉实例间的空间关系和场景的连贯性。在训练阶段,它通过数据增强技术,保证了场景布局的建模效果和模型的广泛适用性。
模型应用前景
单张图像借助MIDI技术,可以制作出高质量的3D场景组合。这项技术在虚拟现实、游戏开发、虚拟实验等多个领域都将扮演关键角色。它能加快创作进程,降低成本,同时增强交互体验的真实性。面向未来,随着技术的不断进步,我们有理由期待它将推动相关产业迅速成长。
你认为MIDI模型将首先在哪个领域展现其卓越效果?期待你的评论分享,同时请记得点赞并分享此文!




